









Platform
LinkedIn Deploys LLM-Based Feed Ranking System to Surface Content Beyond Members’ Networks
LinkedIn has rolled out a new Feed ranking system powered by large language models (LLMs) and graphics processing units (GPUs), replacing a multi-source architecture that the company says created engineering complexity and limited personalization for its 1.3 billion members.
The previous system pulled content from multiple specialized sources, including a chronological index of network activity, trending posts by geography, collaborative filtering, and several embedding-based retrieval systems. Each source maintained separate infrastructure and optimization strategies.
LinkedIn replaced this setup with a unified retrieval system using LLM-generated embeddings. Writing in a March 12 post on the company’s engineering blog, Hristo Danchev, LinkedIn’s TPM Tech Lead, described the core ambition: “What if we could replace this multi-source complexity with a single, unified retrieval system powered by LLM-generated embeddings? And what if those embeddings could capture an understanding so rich that they understood not just keyword matches, but the deeper professional interests that make content relevant?”
The new system addresses cold-start scenarios, where new members arrive with limited engagement history. LLM embeddings allow the system to infer likely interests from profile data alone, without waiting for behavioral signals to accumulate.
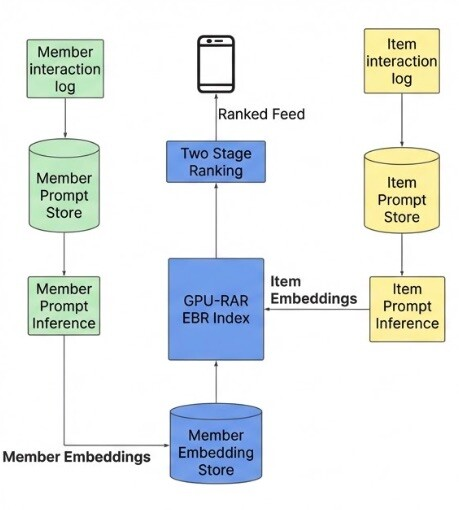
Image: Online system for retrieval and ranking of unconnected content
Source: LinkedIn
Percentile Encoding Drives Retrieval Gains
One technical finding centered on how the system handles numerical features. Initially, raw engagement counts were passed directly into the prompts, resulting in a near-zero correlation between item popularity and embedding similarity scores. LinkedIn engineers addressed this by converting counts into percentile buckets wrapped in special tokens, a change that produced a 30x increase in the correlation between popularity signals and embedding similarity. Recall@10, a standard ranking accuracy metric, improved by 15%.
Sequential Ranking Model Tracks Professional Journeys
On the ranking side, LinkedIn built a Generative Recommender model that treats a member’s feed history as an ordered sequence rather than a set of independent events. The model processes more than 1,000 historical interactions to identify temporal patterns. Danchev noted that “traditional models see three independent decisions; a sequential model understands the trajectory.”
Adding two hard negatives per member during training, defined as posts that were shown but received no engagement, improved Recall@10 by 3.6%. Filtering training data to include only positively engaged content reduced the per-sequence memory footprint by 37% and enabled a 2.6x faster training iteration.
GPU Infrastructure Underpins Production Deployment
LinkedIn’s historical ranking models ran on CPUs. The transformer-based system required a shift to GPU infrastructure, including a custom Flash Attention variant called GRMIS, which delivered a 2x speedup over PyTorch’s standard implementation. The company also built a shared-context batching approach that computes a member’s history representation once, then scores all candidates in parallel.
Three nearline pipelines continuously handle prompt generation, embedding inference, and index updates, keeping feed content fresh within minutes of new activity or profile changes.









